Tuesday, 06 August, 2019
XTDB on Confluent Cloud
 Jeremy Taylor
Jeremy Taylor In this post I will show you how to get going with XTDB and Confluent Cloud to create a highly-scalable unbundled database. XTDB provides an immutable document model on top of Apache Kafka with bitemporal queries (using Datalog) and efficient data eviction. Assuming you have a working knowledge of Clojure, all you need to follow along is 5 minutes and a valid payment method for monthly billing.
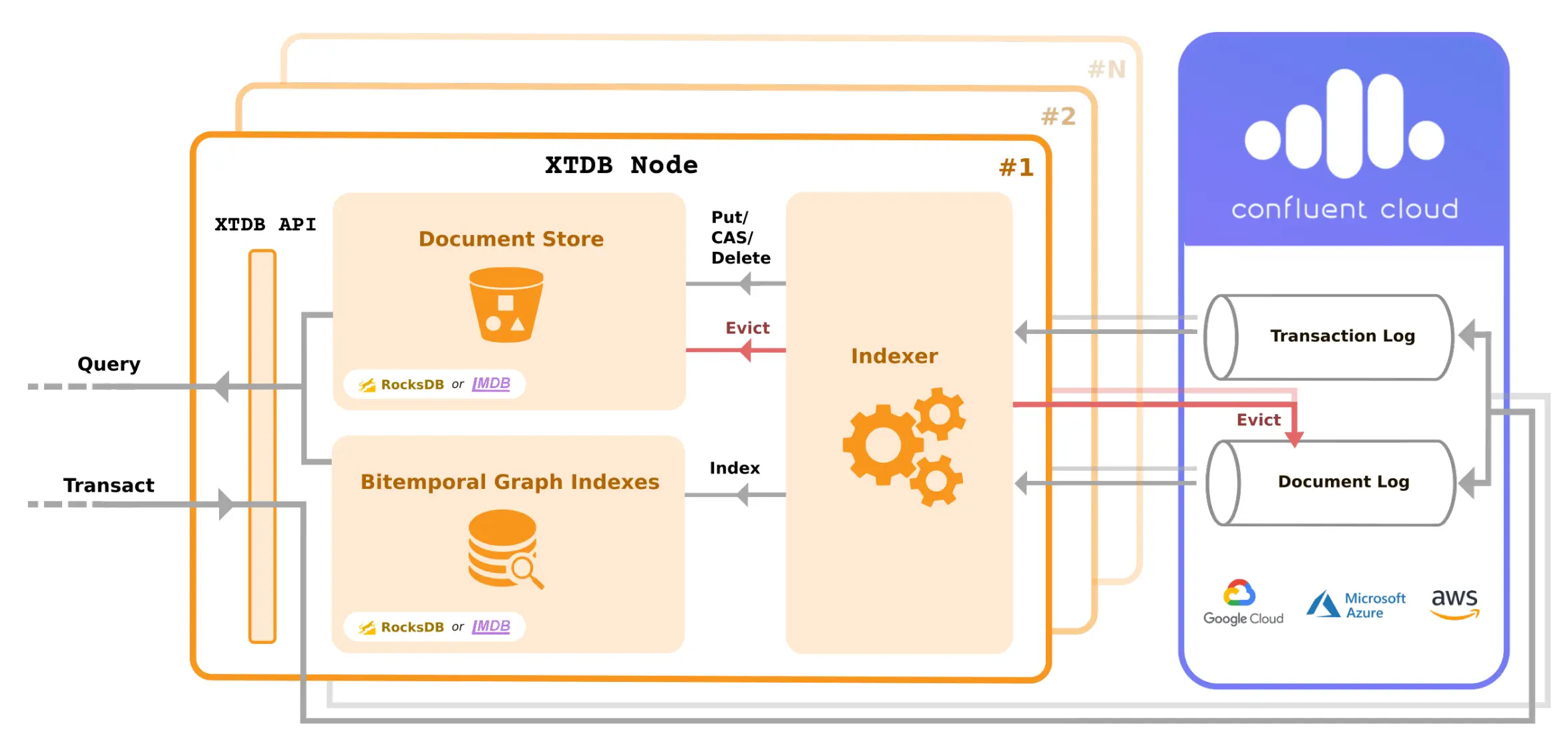
Note that XTDB supports equivalent HTTP and Java APIs, but this post is focussed on Clojure. Also, XTDB nodes may either be embedded in your application instances or made available as a more traditional load-balanced cluster. See the docs for more information about the various deployment options.
Confluent Cloud
Confluent is the primary steward of Apache Kafka and they provide, amongst other enterprise offerings, a fully-managed Kafka service via Confluent Cloud. The latest update to Confluent Cloud is particularly compelling for small XTDB deployments because there are no minimum fees and the pricing structure is very simple:
Monthly Cost = Data In + Data Out + Data Retained
This is a significant milestone in the world of Kafka-as-a-Service (KaaS). There is no longer a need to think about "brokers" or other infrastructure costs. You only pay for what you use and there are no upfront costs or termination fees. The service can be deployed into your choice of GCP/AWS/Azure regions and it scales elastically for up to 100Mbps cluster throughput.
For example, a modest 20GB XTDB database with 5GB ingress and 100GB egress
would currently cost as little as $13.55 / month in the cheapest GCP region
(based on 20*0.10 + 5*0.11 + 100*0.11).
Steps
0. Sign in to Confluent Cloud and create a cluster
Follow the short sequence of sign-up steps to create an account if you don’t already have one: https://www.confluent.io/confluent-cloud/
Once you have to accessed your default environment you can create a cluster.
You will need to choose a name (e.g. xtdb-1), cloud provider (e.g. GCP) and
region (e.g. London). Then you need to provide a valid credit/debit card in
order to create the cluster.
1. Create an API key
Under "Tools & client config" click on the "Clients" tab then "Create New Kafka Cluster API key & secret". Your key and secret have now been embedded in a "Java" configuration snippet on the page. Copy the snippet and save it as a .properties file in a safe location that will be accessible from your XTDB REPL (e.g. /home/myuser/cc-config.properties). Delete the final lines of the file beneath "Required connection configs for Confluent Cloud Schema Registry" - XTDB doesn’t make us of the Schema Registry.
2. Start a Clojure REPL
Refer to the Clojure client documentation if you want to understand the XTDB APIs.
You can launch a clj REPL and provide the latest xtdb-kafka on Clojars using:
clj -Sdeps '{:deps {com.xtdb/xtdb-core {:mvn/version "RELEASE"}, com.xtdb/xtdb-kafka {:mvn/version "RELEASE"}}}'Update the various configuration values in the snippet below according to the
inline comments (for :bootstrap-servers and :kafka-properties-file in
particular) and run the code in your REPL. This will create an XTDB node that is
connected to your Confluent Cloud cluster.
(require '[xtdb.api :as xt])
(def node
(xtdb/start-node
{:xtdb.kafka/kafka-config {:bootstrap-servers "XXXXX.confluent.cloud:9092" ; replace with value from your properties file
:properties-file "/home/myuser/cc-config.properties"} ; replace with the path of your properties file
:xtdb/tx-log {:xtdb/module 'xtdb.kafka/->tx-log
:kafka-config :xtdb.kafka/kafka-config
:tx-topic-opts {:topic-name "tx-1" ; choose your tx-topic name
:replication-factor 3}} ; Confluent Cloud requires this to be at least `3`
:xtdb/document-store {:xtdb/module 'xtdb.kafka/->document-store
:kafka-config :xtdb.kafka/kafka-config
:doc-topic-opts {:topic-name "doc-1" ; choose your document-topic name
:replication-factor 3}}})) ; Confluent Cloud requires this to be at least `3`Submit a transaction:
(def my-doc {:xt/id :some-id
:color "red"})
(xt/submit-tx node [[::xt/put my-doc]]) ; returns a transaction receiptRetrieve the document:
(xt/sync node) ; ensure the node is synchronised with the latest transaction
(xt/entity (xt/db node) :some-id) ; returns my-docYou could even try this from a second REPL with a second node connecting to the same cluster.
Note that the node’s indexes will be in-memory by default and therefore will be recomputed each time you start a node. For persisted indexes that resume when you restart a node you probably want to configure RocksDB as well.
Behind the scenes, XTDB will automatically generate topics with the required retention/compaction configurations and will set the number of partitions for the transaction topic to 1.
You can also create and manage topics independently of XTDB using a CLI tool or the Confluent Cloud web interface, but they may need to be configured according to the latest XTDB defaults (see kafka.clj).
3. Finished
Congratulations! You now have an XTDB infrastructure fit for production
applications. However, if you would still prefer to use a regular JDBC database
(such as SQLite, Postgres or Oracle) instead of Kafka then you may want to take
a look at the xtdb-jdbc module.
In addition to Confluent Cloud’s unique pricing and multi-cloud model you also get access to many interesting non-Apache features. The standard service is probably good enough for most small-scale users of XTDB as it stands, however Confluent Cloud Enterprise offers a number of additional features for large-scale and mission-critical deployments including >100Mbps throughput, multi-zone high availability and ACLs.
Looking Ahead

A common perception of Apache Kafka is that it is not viable for serious consideration unless you have a large enough problem to warrant the non-trivial effort of introducing it into your organisation. Kafka is known primarily for its suitability within large enterprises and web-scale startups. However, with the rise of Confluent Cloud and other commodity KaaS offerings it seems inevitable that perceptions of the broader market will shift, demand will increase, and KaaS prices will be driven down towards the price floors of more common forms of cloud storage. I look forward to seeing a truly cross-cloud service emerge that optimises the use of low-cost tiered storage for infinite retention (a key requirement for XTDB).
In summary, Apache Kafka has never been easier to get started with, whether running it yourself or otherwise, and I strongly suspect that Confluent will continue on its meteoric trajectory. This is all great news for XTDB.
Our official support channel is the 'Discuss XTDB' forum, and we also monitor the #xtdb channel on the Clojurians slack. You can also reach us via hello@xtdb.com.