Tuesday, 12 May, 2020
The XTDB 'Document Store'
 James Henderson
James Henderson We’ve always aimed for XTDB to be 'unbundled' - giving users the choice of which underlying storage engines to use for their specific deployments. Whether it be Apache Kafka, Facebook’s RocksDB or the many supported JDBC backends, XTDB users benefit from decades of development effort put into the stability and performance of these data stores.
We have been busy updating the core components of XTDB to better reflect what XTDB needs from these storage engines, and to make the most of what these engines can provide.
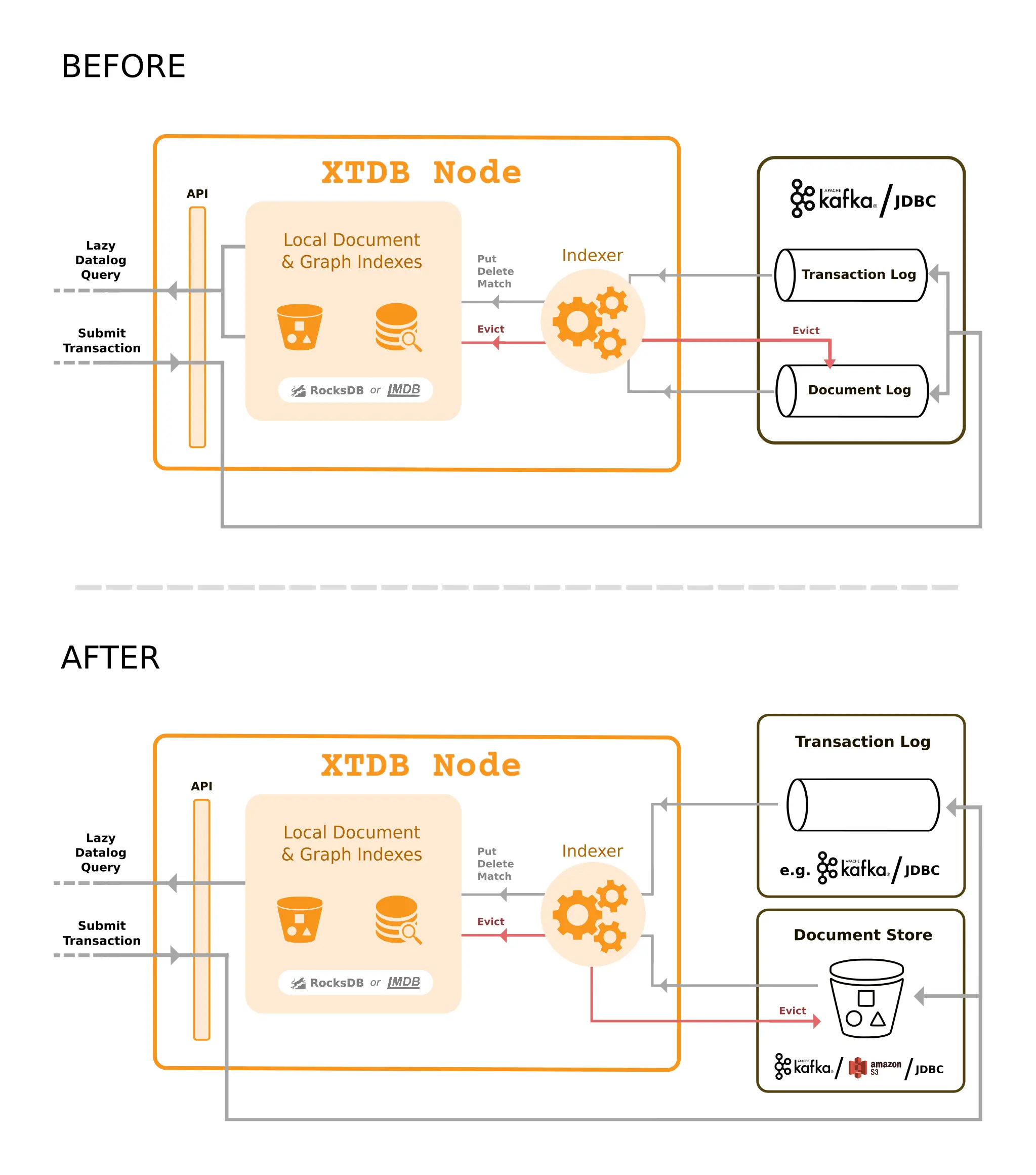
XTDB now supports the concept of a pluggable document store, which is the central location for master document storage in XTDB. You are still able to use an event log such as Kafka to hold all your data, including documents, but you can also use JDBC-based document stores or more cost-effective object storage services like S3. The choice is yours!
Since 20.05-1.8.3-alpha XTDB now has both 'transaction log' and 'document store' protocols:
(defprotocol TxLog
(submit-tx [this tx-events])
(open-tx-log [this after-tx-id]))
(defprotocol DocumentStore
(submit-docs [this docs])
(fetch-docs [this ids]))It is now possible, for example, to use Kafka as the TxLog, and a JDBC database as the DocumentStore, taking advantage of the performance and scaling characteristics of both.
Alongside this change we also released an
S3 document store implementation
for users deploying XTDB within AWS.
This module demonstrates how to implement the protocol and we are excited to see a variety of alternative DocumentStore implementations emerge in the community for other popular storage systems over the coming months!
(UPDATE: we now also have support for Azure Blob Storage following a generous contribution by community member @luposlip)
For more background on why we made this change, let’s start with how XTDB works when processing transactions…
Separating transactions from documents
In XTDB, we make a distinction between a transaction’s operations and its documents - for example, given a transaction of [[::xt/put {:xt/id :luke, :name "Luke"}]]:
-
we hash the
{:xt/id :luke, :name "Luke"}document, giving us"ee9d9c46…" -
we store the document, keyed by its hash
-
we put the transaction operation on the transaction log, but replace the document with its hash:
[[::xt/put "ee9d9c46…"]]
We do this for eviction - this distinction between documents and transactions means that, if Luke were to request that we irretrievably remove all his data (e.g. due to a GDPR/CCPA request), we only need to forget the content of the document and the transaction log can stay immutable.
When the indexer receives one of these 'evict' transactions, it not only has to remove the data from its indexes, it also has to request that the pluggable transaction log component do the same.
Consuming the transaction log
In Kafka (one implementation of this transaction log), we achieved this using two topics - one immutable 'tx-topic' to queue the operations, one mutable 'doc-topic' with the documents.
This is optimal for users who want to keep all their data on Kafka as the primary golden store, but other groups of users may want to take advantage of other stores and to reduce their Kafka foot-print. Ultimately there is no one-size-fits-all and what users want is more configuration flexibility.
Now we’ve separated out these two golden stores: the 'transaction log' and 'document store'. This simplifies the overall architecture of XTDB and gives users more flexibility in defining their own XTDB topologies.
Demo
For an overview and demo of the S3 module, see this excerpt from our recent Development Showcase:
(Because of the immutable nature of YouTube videos, you’ll note XTDB is still referred to as "Crux" in the video and the title.)
Get in touch!
Please let us know if you’ve got any thoughts or questions about this change - we can be contacted through all of our usual channels.
-
The #xtdb channel on Clojurians Slack
Cheers and have fun!
XTDB Team