Thursday, 13 August, 2020
Transactional Extensibility
 James Henderson
James Henderson In the latest releases we added 'transaction functions' and 'speculative transactions' to XTDB - a potent combination of features!
Transaction functions are user-supplied functions that run on the individual XTDB nodes as a transaction is being processed. As XTDB ingests only ever transactions in serial, directly based on the order of transactions on the transaction log, this is an ideal time (for example) to safely check the current database state before applying a transaction, for integrity checks, or to patch an entity.
Speculative transactions allow you to see what the results of your queries would be if a new transaction were to be applied, without persisting the changes or affecting other users of the database.
“What if” queries are a frequent requirement; they’re used to explore the effect of making certain changes without actually having to make (and subsequently unmake, possibly) the changes in question.
2nd Edition by C.J. Date
This capability is also valuable during REPL-based development and for expressing integrity constraints using Datalog.
For those who like to dive a bit deeper, we’ve also made it easier to write your own transaction consumer - more on this below.
Transaction Functions
In the most recent dev diary we shared some details on why and how we implemented transaction functions, but let’s recap on their day-to-day usage.
We first submit the transaction function to the database as we do any other document.
Transaction function documents have a :xt/id to identify the function, and a :xt/fn key containing the function body (currently on Clojure is supported).
A transaction function takes a 'context' parameter as its first argument, which you can use to obtain a database value using xtdb.api/db - we use it here to get the current version of the entity.
A transaction function can also accept any number of additional parameters, and when invoked it is normally expected to return a vector of basic transaction operations which get indexed in the usual way.
If the transaction function invocation returns false or throw an exception, the whole transaction will roll back.
Here’s an example of a transaction function that increments an entity’s :age key:
(xt/submit-tx node [[::xt/put
{:xt/id :increment-age
;; note that the function body is quoted.
;; and function calls are fully qualified
:xt/fn '(fn [ctx eid]
(let [db (xtdb.api/db ctx)
entity (xtdb.api/entity db eid)]
[[:xtdb.api/put (update entity :age inc)]]))}]])If we didn’t use a transaction function for this, we might be tempted to run a normal query to get the entity’s age, then submit a transaction with the incremented age - but this would be vulnerable to a race condition if two processes both tried to change the same entity at the same time. An ::xt/match transaction operation could be used to atomically validate that the previous age value is unchanged, but that would not be an efficient or elegant solution for something as primitive as a counter.
By using a transaction function here instead, we can ensure that each process will always read-then-write the latest version of the entity.
We may then invoke this transaction function in a later transaction using the ::xt/fn operation, passing it any expected parameters:
(xt/submit-tx node [[::xt/put {:xt/id :ivan, :age 40}]])
;; `[[::xt/fn <id-of-fn> <args*>]]`
(xt/submit-tx node [[::xt/fn :increment-age :ivan]])When invoked by the indexer, the transaction function will return a vector containing a single put operation, as specified by our function body. This vector is equivalent to what the indexer will see and subsequently go on to process as normal:
;; [[::xt/put {:xt/id :ivan, :age 41}]]After those three transactions have been indexed we should see that Ivan’s age has been incremented:
(xt/entity (xt/db node) :ivan)
;; => {:xt/id :ivan, :age 41}Job done!
Another intriguing aspect is that the returned vector of operations could in turn include further transaction function invocations which will also get processed. This basic recursive property allows you to create rich hierarchies of transaction function logic that ultimately expands into a standard vector of basic operations.
Behind the scenes the 'argument documents' supplied to the invocation operations (arguments get stored as documents!) are replaced with the resulting operations the first time they are processed. This allows XTDB to avoid needlessly re-executing transaction functions during subsequent processing of the transaction log.
Speculative Transactions
When you apply a speculative transaction a new database value is synchronously returned. You can then use this value to make queries and entity requests as you would any normal database value. Only this local value observes the effects of your speculative transaction - neither the transaction or its effects are submitted to the cluster, and they’re not visible to any other database value in your application.
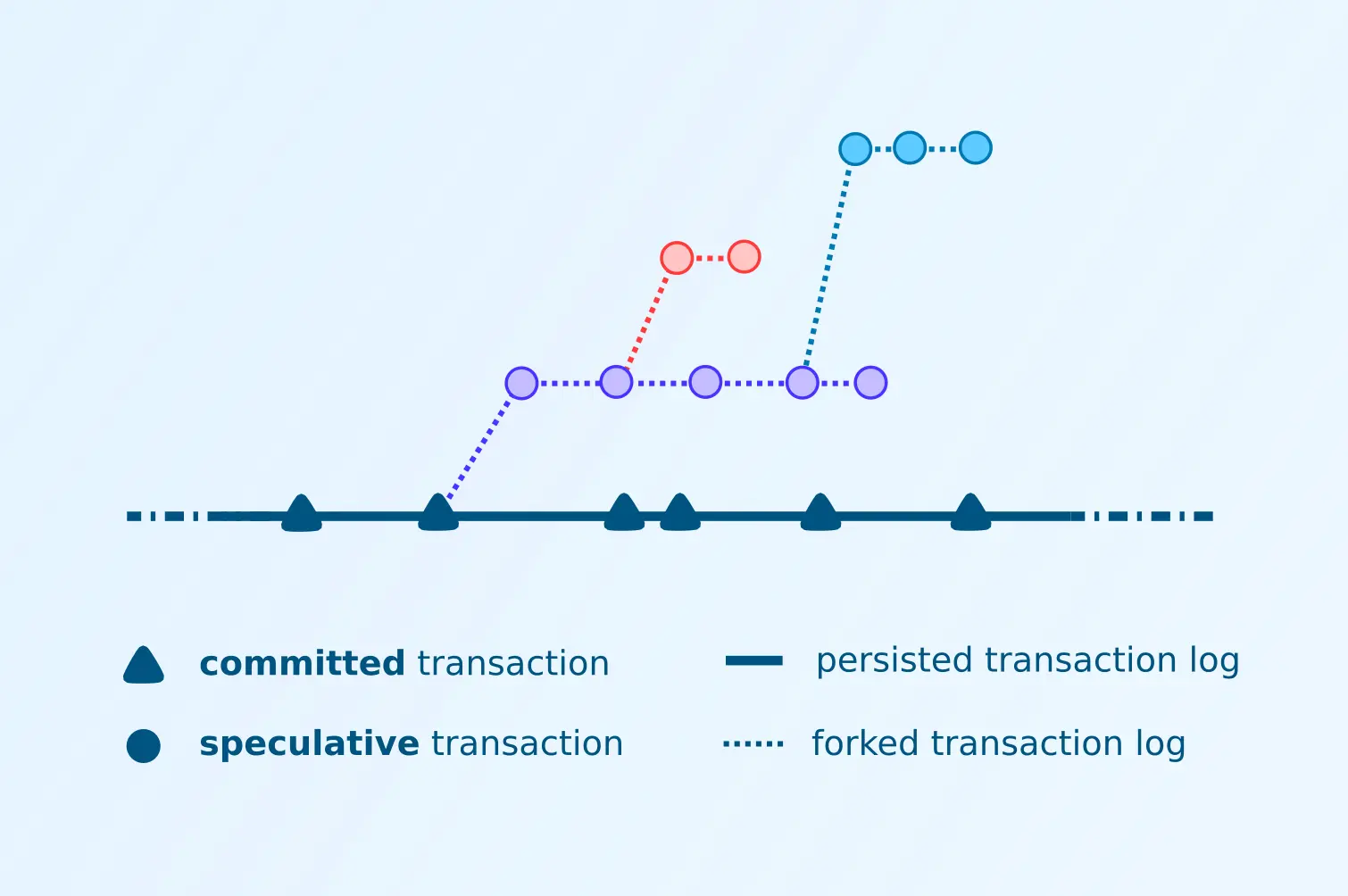
We apply these transactions to a database value using with-tx:
(let [real-tx (xt/submit-tx node [[::xt/put {:xt/id :ivan, :name "Ivan"}]])
_ (xt/await-tx node real-tx)
all-names '{:find [?name], :where [[?e :name ?name]]}
db (xt/db node)]
(xt/q db all-names) ; => #{["Ivan"]}
(let [speculative-db (xt/with-tx db
[[::xt/put {:xt/id :petr, :name "Petr"}]])]
(xt/q speculative-db all-names) ; => #{["Petr"] ["Ivan"]}
)
;; we haven't impacted the original db value, nor the node
(xt/q db all-names) ; => #{["Ivan"]}
(xt/q (xt/db node) all-names) ; => #{["Ivan"]}
)The 'making-of'
Behind the scenes, both of these features have benefited from refactoring how XTDB indexes transactions. Even before these changes, to correctly index a transaction, we’ve needed to ensure that a later transaction operation sees the updated indices from earlier operations within the transaction - but also that these updates aren’t persisted before the transaction atomically commits. Indeed, transaction operations themselves need to make similar (albeit lower level) history requests of the indices, to ascertain the current state of the entities in question before making their updates.
For example, a put operation with a start and end valid-time specified looks at the current timeline of the entity between those times (using similar functions to those found on our public history API), and then uses this to assert a new timeline at the current transaction time.
This both allows queries after the transaction to reflect the new timeline, whilst also allowing you to go back in transaction time and see the timeline before that update - the 'crüx' of our bitemporality!
This internal history API, then, needed to reflect both the persisted state of the indices and the transient updates introduced by earlier transaction operations. It did this, essentially, by merging two indices (one on-disk, one in-memory) to make them look like one index - our indices are an ordered trie structures so this is a relatively straightforward operation. When a transaction is ready to commit, we write the changes accumulated within the in-memory indices to the on-disk indices.
We then realised that if we threw these changes away rather than applying them to the on-disk indices, this looks a lot like 'speculative transactions' - handy!
In refactoring this area, we’ve also managed to surface a few of the lower level primitives of XTDB transaction consumption.
The main primitives here are begin-tx, index-tx-events, commit and abort, called as follows:
(require '[xtdb.api :as xt]
'[xtdb.db :as db])
(let [tx (db/begin-tx tx-ingester {::xt/tx-time ..., ::xt/tx-id ...})]
(if (db/index-tx-events tx evts)
(db/commit tx)
(db/abort)))This can then be incorporated into a transaction log implementation as required - for example, Kafka and JDBC both have something akin to this in a polling loop, standalone calls it directly from a single-threaded queue consumer - other suitable transaction logs may work in a more reactive style. For a complete example, have a look at the JDBC transaction log’s usage of the XTDB polling consumer.
The existing transaction consumers are all now written in terms of these primitives - but, more importantly, this change opens up the possibility of new implementations from explorers willing to dive into the XTDB internals. Indeed, if there’s demand from the community, we can look to stabilise this as a public API. As always, let us know - we’re happy to help out, and we’re certainly excited to see what you build!
Getting in touch
We can be contacted at hello@xtdb.com, or through our the 'Discuss XTDB' forum. We also frequent the #xtdb channel on Clojurians' Slack.
Cheers!
The XTDB Team.