Tuesday, 04 June, 2024
Development Diary #12
 James Henderson
James Henderson When I started writing this dev diary, I looked back at the timestamp of the previous one to see how long it’d been - apparently we’ve been very busy!
Before I start with the XTDB news, last month we also enjoyed the fantastic JUXT XT24 conference. Malcolm and Jeremy gave a talk on 'Financial use-cases for an immutable database', in which they discussed the context and motivation for writing XTDB.

I also gave a lunch-n-learn on 'XTDB: Under the Hood' covering the new indexing structure in XT2, and how it’s particularly suited to storing bitemporal, historical data while still maintaining fast access to the current state.

Videos for both of these will be available soon!
Playtime!
For those who don’t yet have a local XTDB project, we’ve been working on a zero-install, online XTDB playground.
You can try out everything below at https://play.xtdb.com:
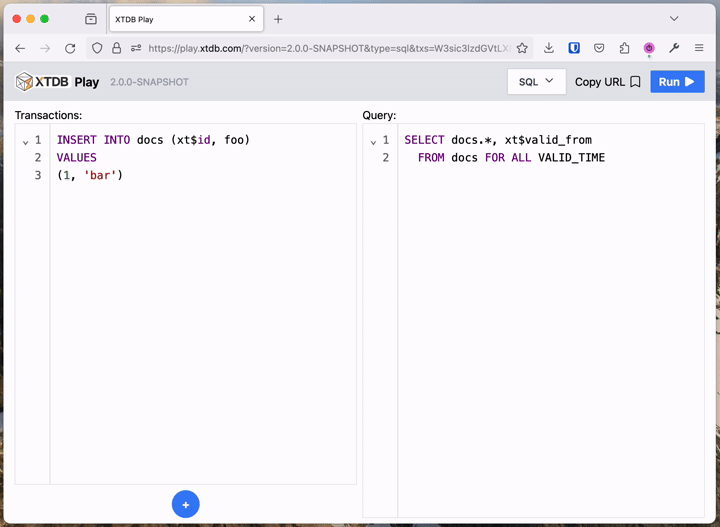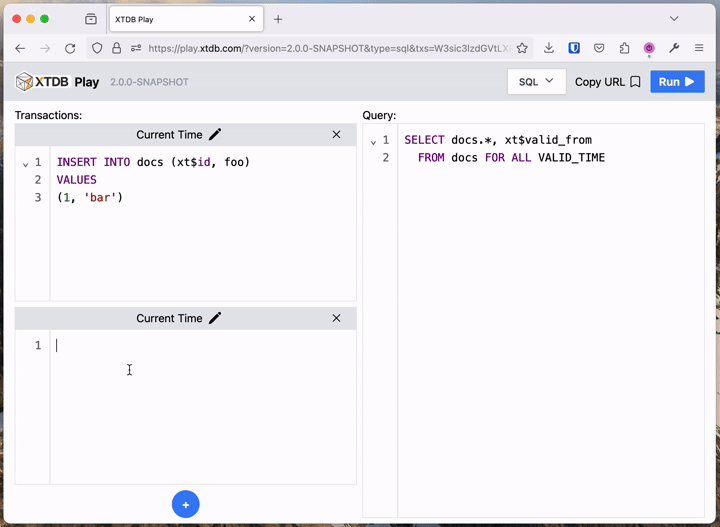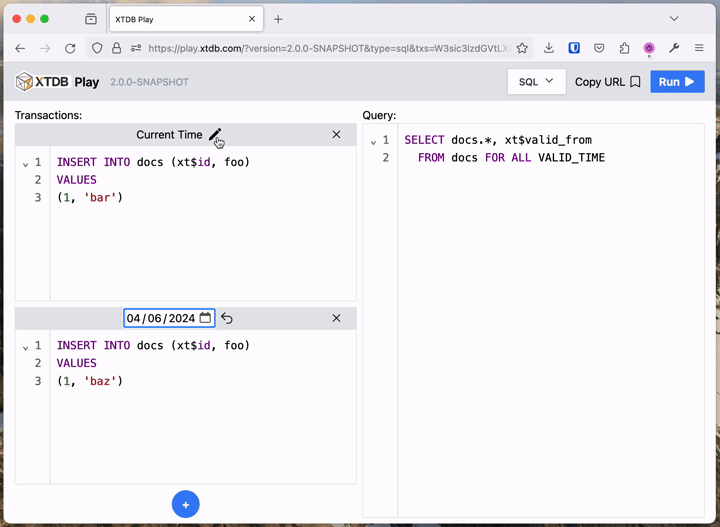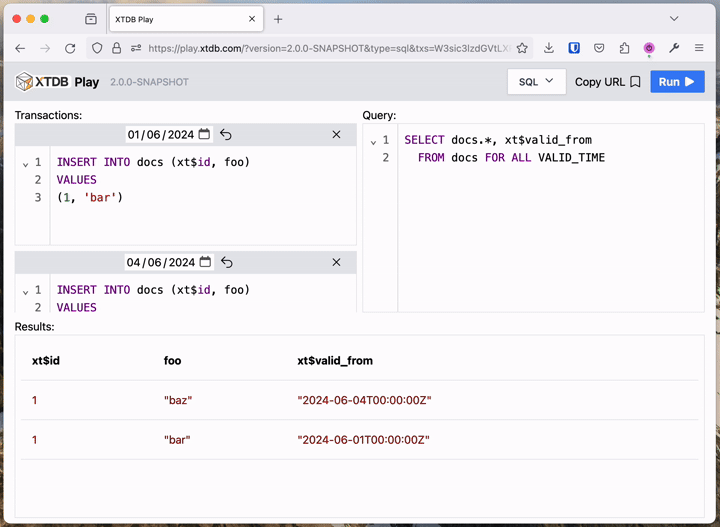
XT Play leans heavily on the ease of creating transient XTDB nodes - every request made starts up an in-memory node, executes the transactions, runs the query, and shuts down the node, all in the time it takes to serve your HTTP response. We make a lot of use of this in our own tests - frequently, we’ll have a test fixture that does exactly this for each test, or we’ll use something similar at a REPL:
(require '[clojure.test :as t]
'[xtdb.api :as xt]
'[xtdb.node :as xtn])
(def ^:dynamic *xt*)
(defn with-xt-node [f]
(with-open [xt (xtn/start-node)]
(binding [*xt* xt]
(f))))
(t/use-fixtures :each with-xt-node)
(t/deftest test-xtdb-round-trip
(xt/submit-tx *xt* [[:put-docs :foo {:xt/id 1, :value 24}]])
(t/is (= [{:value 24}] (xt/q *xt* "SELECT value FROM foo"))))
;; or, from the REPL (a 'Rich' comment):
(comment
(with-open [xt (xtn/start-node)]
;; ...
))Obviously feel free to re-purpose this example in your own project!
Nested query results
EDN Datalog users will no doubt be familiar with pull - a powerful tool for returning GraphQL-like nested data structures from your database.
We’ve recently incorporated this into our SQL dialect, significantly reducing the amount of SQL it takes to return nested maps and arrays.
Normally, in SQL 'scalar' sub-queries, you have to ensure that the sub-query returns exactly one column, and at most one row.
We’ve introduced NEST_ONE and NEST_MANY, which automagically wrap multiple columns and multiple rows into nested data structures.
Let’s say you have the traditional 'customers' and 'orders', and you want to render a webpage showing the customer details and their three most recent orders - you can achieve this using NEST_MANY.
NEST_MANY takes a SQL sub-query that returns potentially many columns and potentially many rows, and wraps them up into an array of objects:
-- one -> many
SELECT c.xt$id AS customer_id, name,
NEST_MANY(SELECT o.xt$id AS order_id, value
FROM orders o
WHERE o.customer_id = c.xt$id
ORDER BY order_date DESC
LIMIT 3)
AS orders
FROM customers c
-- => #{{:customer-id 0, :name "bob", :orders [{:id 1, :value 8.99} {:id 0, :value 26.20}]}
-- {:customer-id 1, :name "alice" :orders [{:id 2, :value 12.34}]}}Notice that (unlike traditional 'pull') you have the full power of a subquery here, to order by the order-date and limit it to 3 orders for each customer.
In the other direction, many → one, we use NEST_ONE - this takes a sub-query that returns potentially many columns and 0-or-1 rows, and wraps that row into a single nested object:
-- many -> one
SELECT order_id, value,
NEST_ONE(SELECT name FROM customers c WHERE c.id = o.customer_id) AS customer
FROM orders o
-- => #{{:order-id 0, :value 26.20, :customer {:name "bob"}}
-- {:order-id 1, :value 8.99, :customer {:name "bob"}}
-- {:order-id 2, :value 12.34, :customer {:name "alice"}}}More SQL
In addition to nested data structures, we’ve also made a number of other SQL improvements:
-
You might have noticed the lack of fully-qualified columns in the above examples - where before we required you to fully-qualify each column (
SELECT foo.a, foo.b FROM foo), we now do enough schema inference and query analysis to know which table each column refers to, even in the absence of the traditional up-frontCREATE TABLE. Safe to say, for a relatively small-looking change, removing a few characters from your queries, this took a non-trivial amount of dev work - especially for a database that started off without explicit tables at all! We’ve added Snowflake-styleEXCLUDEandRENAMEtoSELECT *- e.g.SELECT * EXCLUDE xt$id RENAME (value AS foo_value) FROM foo -
We’ve added numerous Postgres-compatible functions, including infix regex operators (
~,~*and friends) and infix casting ('12'::int). -
We’ve added a
UUIDliteral -SELECT * FROM users WHERE xt$id = UUID '7ad9dea8-11ce-4999-95a5-ba742d5a3dd2' -
SELECTis now optional - if it’s omitted, it defaults toSELECT *
What’s next?
We’re currently on the lookout for XTDB Design Partners - people to help us shape the future of XT. When working with you as a design partner, we’ll additionally invest development time and prioritise our roadmap to help meet your requirements.
To get involved, fill in this small form and we’ll get in touch.
As always, feel free to email us at hello@xtdb.com, or join the discussion at https://github.com/orgs/xtdb/discussions
Cheers!
James & the XT Team