Thursday, 12 June, 2025
Launching XTDB v2 — time-travel SQL database to simplify compliance
 Jeremy Taylor
Jeremy Taylor XTDB is designed to simplify development, reporting and compliance for immutable systems. Unlike other SQL databases, XTDB tracks both 'system time' and 'valid time' automatically, building on the core ideas in SQL:2011 — no triggers, no history tables, no hacks. All tables are bitemporal tables.
A preview of XTDB v1 launched on 19th April 2019 - with a firm mission to reduce the pains of dealing with time - and today we’re extremely excited to announce our first stable release of XTDB v2!
This means that we have arrived at a stable SQL API and storage format that we’re prepared to support for a long time. The team is committed to supporting open source users, and we are excited to see what people end up building in the wild.
We have already been collaborating closely with Design Partners over the past year who have now deployed v2 into production.
As ever, all code is open source: https://github.com/xtdb/xtdb (MPL 2.0 license)
The rest of this post provides some backstory, a snapshot of our current thinking on how XTDB compares with other systems, and an overview of how its various features support the mission.
In a nutshell - XTDB v2:
-
Makes bitemporal SQL practical - without schema pain or audit hell - by tracking both 'system time' + 'valid time' automatically
-
Helpful for developer productivity and peace of mind
-
Good for businesses that really value auditability
-
-
Offers a PostgreSQL-compatible SQL interface (although 100% compatibility is not the goal)
-
Executes queries using immutable Apache Arrow data and object storage
-
Is Open Source, Production-Ready, and Helps Developers To Avoid Reporting Headaches
Until Now
Since the dawn of relational databases, the question of how best to deal with data that changes over time has been left unanswered.
Coping mechanisms like 'snapshots', 'history tables', 'soft deletes', and timestamped version columns are symptoms of a universal pain and major source of incidental complexity: SQL databases don’t adequately support users with managing changing data.
Consider this basic before/after example of querying history:
-- Instead of setting up various triggers and tables,
-- only to then write queries like...
SELECT * FROM users_history
WHERE id = 42 AND valid_at <= '2024-01-01'
ORDER BY valid_at DESC
LIMIT 1;
-- How much simpler could things be if you could easily do it like this?
SELECT * FROM users FOR VALID_TIME AS OF '2024-01-01' WHERE id = 42;The ability for a user of an application to ask questions like "what did my data look like as-of 10 minutes ago?" is an exercise left firmly in the hands of software developers who must carefully craft such requirements into the database schema and querie, in advance. Coping mechanisms are often retro-fitted after an initial design has already shipped, at great cost and with varying success.
While some database systems have added native 'temporal table' support and there are various Postgres extensions that can help somewhat, these remain specialist features requiring upfront thinking and are not commonly appreciated or adopted in practice.
Bitemporal = More Than Immutable
Prior to joining forces to build XTDB, our team’s practical appreciation for 'temporal' problems was quite diverse, however we were fortunate to share a common belief in the importance of immutability when building systems - where thinking about software in terms of a single, serial history of state changes is about as simple as you can get (credit to Rich Hickey for all his expositions surrounding Clojure and Datomic!).
In the abstract, an 'immutable database' (such as Datomic, or XTDB) allows you to reference previous states without stateful coordination or excessive resource consumption (i.e. append-only ledgers or long-running read transactions don’t count). Achieving even the most primitive feeling of immutability using regular SQL database statements requires a whole heap of upfront complexity (triggers, timestamp gymnastics, schema changes etc.), and the complexity builds up fast.
Our team encountered a series of complex reporting requirements whilst building back-office trade and risk systems at investment banks, where the existing SQL systems and overall approaches were struggling to scale. We came to recognise that a common endgame for tricky timestamp and immutable update logic was the notion of 'bi-temporal' change tracking. Then, as you may have guessed already, we started doing some research…
Back in 1985, Richard Snodgrass published precise descriptions of the importance of two common kinds of time-keeping within database: the 'System Time' (aka 'Transaction Time') which is the wall-clock time when data enters the database, and the 'Valid Time' of a tuple over a historical view of the user’s data timeline.
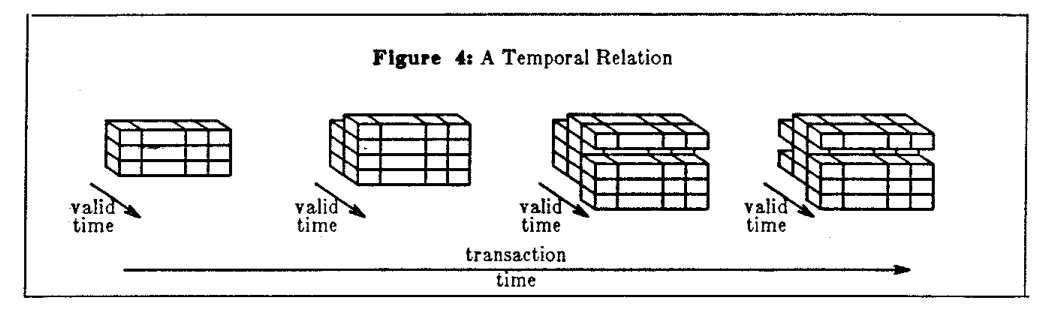
-
System Time enables 'rollback' queries and operations, which is invaluable for auditing and debugging.
-
Valid Time enables the recording of 'retroactive' changes, to account for corrections and late-arriving data.
The combination of both dimensions applied at the granularity of each row allows your database to reflect an accurate view of what your organization knew to be true at any given moment (potentially across disparate upstream systems, and compensating for various delays and synchronisation steps), and an auditable account of how that knowledge evolved. No need for explicit snapshots and copies.
This 'bitemporal model' of data allows users to ask sophisticated questions like "how did my data look as-of the reporting timestamp 10 minutes ago (a point in valid time), comparing as it was known at the time (the system time 10 minutes ago) with all backdated changes (the latest system time)?"
Software that can support these kinds of questions using concise query logic is worthy of the 'time-travel' label.
SELECT with_changes.*
FROM docs FOR VALID_TIME AS OF (NOW - INTERVAL 'PT10M')
FOR SYSTEM_TIME AS OF (NOW - INTERVAL 'PT10M')
AS without_changes
JOIN docs FOR VALID_TIME AS OF (NOW - INTERVAL 'PT10M')
AS with_changes
USING (_id)
WHERE without_changes.col1 <> with_changes.col1;(you can Play with this example)
Bitemporal or Bust
General interest in the bitemporal model accelerated in the wake of the 2008 Global Financial Crisis, as regulations evolved to ensure that the financial sector became more resilient and transparent for scrutiny by third parties. Many new reporting systems were built, often performing expensive risk calculations, and underpinned by pairs of 'as-of' timestamps at for keeping track of data as it flows around systems.
Since then however, and despite a period of modest momentum around the SQL:2011 specification by a handful of database vendors, businesses who operate critical financial systems have been left without real help from databases to ensure that as-of reporting is both accurate and cost-effective to implement as a matter of course.
Instead, developers working in domains where getting temporal modeling correct matters are forced to make do (along with everyone else) and build on the "update-in-place" (destructive mutation) paradigm of UPDATE and DELETE statements of classic SQL. There is little alternative to building and maintaining a mess of timestamp columns and triggers alongside enormously complex queries (which typically need filters and indexes on every join).
The update-in-place SQL paradigm definitely made more sense 50 years ago when storage was an expensive resource, but saner defaults have long since been possible and now, through XTDB, we are demonstrating a vision of what can be possible if we make the bitemporal model first-class within our databases.
How XTDB Helps
XTDB is a database designed to give businesses confidence by ensuring timely and efficient auditability of systems. With v2, we are taking the bitemporal vision mainstream via a first-class SQL API with PostgreSQL compatibility to aid familiarity and adoption.
This is achieved through the following key features of XTDB’s design:
-
All tables are SQL:2011 bitemporal tables - With XTDB, developers are no longer the bottleneck for implementing history requirements. As a developer, UPDATEs and DELETEs appear to work as you’d expect, but the old data is always available, only hidden behind built-in timestamp columns that get filtered out by default. Strong auditability is achieved by transparently recording all changes to data, including retroactive backfills and corrections to past states, and by extending SQL with additional 'temporal' operators.
-
This is all enforced universally and doesn’t clutter or further complicate your schema, which is unlike the SQL:2011 standard tha introduced syntax for handling bitemporal data, but didn’t make it easy to use.
-
When you build an application with XTDB you don’t have to think about bitemporal modeling at all - it’s just there ubiquitously, tracking history in the background and available to query whenever you need to reach for it.
-
-
Similar to a time series database, but not the same - With XTDB you don’t have to model your data using tables of append-only events, instead you’re able to work in terms of current states just as you would in Postgres.
-
In XTDB, all joins are as-of joins, accurate to a single microstamp 'snapshot' timestamp (filtering using System Time columns), and this allows historical queries to be re-run as many times as needed without affecting concurrent writes.
-
Unlike time series databases which are optimized mainly for observability use cases, where the drive for handling petabytes of low-value data often means sacrificing various ACID properties for performance, XTDB is first and foremost built to handle high-value transactional data that demands accuracy - such as financial trades and other kinds of highly regulated records.
-
An 'event' in XTDB is best modelled as a record with a Valid Time duration of 1 microsecond (or some other finite duration), in dedicated events tables.
-
-
XTDB implements Serializable isolation, with reified transactions that can tie changes back to individual transactions. This is very similar to Datomic. You can always be sure that one transaction occurred before another, no matter which node you’re connected to.
-
To bring this all to life and push down the temporal concerns as far as possible, we built a ground-up new query engine and schema layer on top of Apache Arrow on the JVM, using a combination of Clojure and Kotlin.
-
-
Reads scale horizontally via object storage where a separation of storage and compute allows the LSM-tree primary temporal index structure to be cached efficiently across many nodes. Spinning up new compute nodes for ad hoc audit queries is therefore fast and efficient - a promising foundation for 'serverless' operations.
-
Optimized for time-partitioned columnar storage but retains fast lookups of individual rows due to the use of a trie branching technique throughout the LSM levels that combines a temporal heuristic with comprehensive use of UUIDv4 IDs.
-
Complex analytical queries involving many scans over the columnar data (stored as Apache Arrow) take into account metadata to avoid downloading irrelevant historical data where possible.
-
XTDB aims to satisfy the HTAP argument of "why use two databases if you can get away with one?". It seems that using Change Data Capture to pipe data from a transactional database system into a data warehouse or data lake is an increasingly common practice, but it is probably not necessary in many cases. And that pattern doesn’t help when you get new requirements like "please can you add an 'undo' button". We argue that every application should be built on a database that stores history.
-
-
Built around modern principles of immutability and the assumptions that mass storage is effectively free for most structured data use cases.
-
Built for dynamic data - XTDB is able to handle many shapes of data simultaneously without prior schema declarations. Evolving data can be wide or highly nested, and still processed via a unified SQL paradigm - no need for awkward JSONB columns!
-
Everything is open source and runs in Kubernetes
Developer Perspective: Important if not Urgent
Beyond a minority of similar vertical use cases where the need for rich auditability is very clear cut (see also: SIEM), any sense of urgency to invest energy on nuanced reporting requirements is typically overshadowed - at least from the perspective of developers - by the many essential complexities of building working software applications. Coping with a few extra timestamp columns and history tables can be 'good enough' for many, no doubt.
The answers to many questions like "did we meet our KPI targets last week?" may never need to be 100% accurate or perfectly reproducible.
However, regardless of where your industry sits today, in a world with ever increasing regulatory oversight, whenever you decide to use a 'current time' database like Postgres just be mindful that a non-trivial amount of work has to happen to make sure you retain sufficient audit logs and views over history to be prepared for the future.
Organizations should feel able to respond quickly as new reporting requirements can emerge without warning. And if your application has reporting requirements of any kind, then a bitemporal data model can dramatically simplify how you address them.
Note that having some separate data warehouse/lake with Change Data Capture is not some magic solution if the application isn’t keeping track of history properly in the first place - introducing an analytical database into this picture will only be moving the problems of time and correctness around at a superficial level.
Decision Maker Perspective: Critical
Another lens for considering the value of bitemporal model is to understand that some data simply matters more than other data.
Understanding the 'current state' of a modern business requires integrating data from many disparate sources, ultimately ending up as some kind of report on somebody’s desk (or metaphorical equivalent). Ideally the person receiving the report knows that information in a report can never be 100% accurate, and shouldn’t ever be fully trusted.
How then is that person able to make decisions based on potentially faulty information? Reports for a given time period may need to be re-run ('re-reported') in order to account for processing mistakes and late arriving information, but it’s all just a never-ending quest to model the world perfectly.
Thankfully, in aggregate, the world seems to muddle along okay with imperfect databases and educated guesses, but every so often something bad happens. Then the blame games start, and people responsible for fixing things need to be able to quickly discern the good decisions from the bad.
The trouble is, it’s very hard to prove anything about the contents of the reports that (in theory, at least) drive decision making processes when all the source data has disappeared, or the pipeline of batch processes required to generate the report take weeks to manually reconstruct. And so, the world is built on trust.
Or at least, most of the world is built assuming a high degree of trust. In some domains, particularly regulated domains (finance, insurance, healthcare etc.), the trust must be backed up with huge investments into IT systems to be able to reconstruct past system states and understand what data might have fed into non-trivial business decisions (or indeed life-and-death decisions).
Quite rightly too. In a world where the flows of information hold more power than ever, it is important that decision makers of all shapes and sizes can be held to account. Stakeholders (managers, regulators, customers etc.) want to be able to ask forensic questions like "what did you know, and when did you know it?" across all software systems as a matter of course - and not only in exceptional circumstances that justify the huge costs of manual data reconstruction.
Helping AIs to Understand Time?
Perhaps the most exciting aspect of adopting a database like XTDB is the potential for entirely new upsides that having a complete temporal history of your database readily available could unlock. For example, the training of AI.
Training AIs often demands access to granular history, to be able to time-travel and learn the patterns of your business. It’s also important to be able to reproduce the history supplied for training, even as it undergoes corrections and expansion, otherwise it’s hard to judge the effectiveness of changes to algorithms, or build meaningful interpretability. Hopsworks discussed these aspects at length in their SIGMOD '24 paper on their 'feature store' architecture.
In any such architecture, an effective means of partitioning history across low-cost object storage is essential to control costs. Many other feature stores, like Tecton and Feast, have also arrived at similar conclusions.
In contrast to these highly specialized systems (which are undoubtedly very effective at keeping expensive GPU farms serviced at scale), XTDB can provide access to application history with minimal effort and without the need to introduce sophisticated data pipelines and tools.
Any ability to generate reproducible, time-aware snapshots of any data is ideal for building transparent training pipelines where data provenance matters.
Beyond training, the bitemporal data model at the core of XTDB has always been intended to help humans make better decisions. In a modern context we believe it should also serve well as both the basis for AIs to better understand a changing world - both during training and after deployment - and also as a means for humans to understand the AIs in turn. Particularly as AI agents begin to join the ranks of important decision makers!
With XTDB, simple SQL queries can efficiently reconstruct (via temporal joins) the entire state of the world as-of successive moments in time (as best known, or using fixed snapshot timestamps), without headaches or major storage overheads:
SETTING
DEFAULT VALID_TIME AS OF TIMESTAMP '2024-03-08 16:30:00Z',
SNAPSHOT_TIME TO TIMESTAMP '2024-04-01Z'
SELECT
ct._id as trade_id,
ct.symbol,
ct.quantity,
ct.price as trade_price,
csp.spot_price,
ct._valid_from as trade_timestamp,
csp._valid_from as spot_price_timestamp
FROM commodity_trades AS ct
INNER JOIN commodity_spot_prices AS csp
ON ct.symbol = csp._id;(you can Play with this example)
Next Up
Over the coming months we plan to work on a couple of large projects in particular: adding support for multiple databases (potentially across independent object storage buckets) and various aspects of authentication and authorization. We also plan to spend time on validating new Postgres drivers/tools and expanding our documentation around FlightSQL, in addition to the regular fixes and performance improvements. For the latest view of epics, see here.
Do you work in a highly regulated industry? Can you see XTDB helping? We would love to hear from you! Please consider applying to our Design Partner programme to help shape a new era of time-aware database technology!
For monthly updates on the project progress, please join our email newsletter which will be rebooting in earnest next month: here
