Tuesday, 06 May, 2025
UPDATE RECONSIDERED, delivered?
 Jeremy Taylor
Jeremy Taylor I recently came across a copy of a rather obscure paper titled "UPDATE RECONSIDERED" (1977) and felt inspired to attempt to help popularize its story and discuss its prominence, as it relates to both wider trends in database technology and XTDB.
A recorded presentation on this paper and blog post is also available:
The origins of LSM Trees
Before we go all the way back to 1977, let’s start with a slightly more modern topic: LSM Trees.
Log-Structured Merge (LSM) trees were first proposed in 1992 by Patrick O’Neil et al. to optimize write performance in database systems. Unlike traditional B-trees, which incur random disk writes, LSM trees batch updates in memory and flush them as sequential writes to disk, greatly reducing write latency. This made them ideal for workloads with high write throughput.
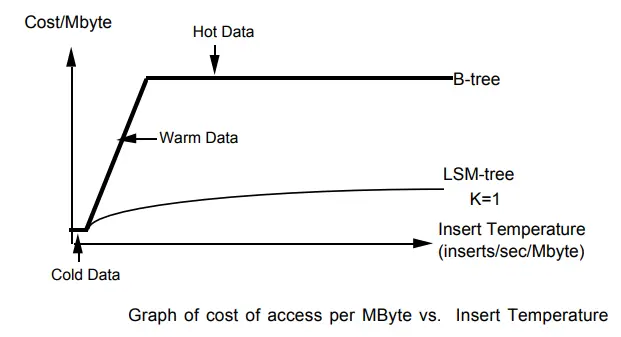
LSM trees gained widespread traction in the 2000s and 2010s as web applications demanded faster, more scalable storage solutions. Google popularized the model with Bigtable, its distributed database that inspired open-source systems like Apache HBase. Facebook advanced the field with RocksDB, a high-performance key-value store based on LevelDB, tailored for flash storage and embedded use. Amazon’s DynamoDB and ScyllaDB (a high-performance rewrite of Apache Cassandra) also rely on LSM trees for their core storage engines.
The industry backing for LSM-tree-based systems is massive: Google, Facebook, Amazon, Microsoft (via Azure Cosmos DB), and Apple have all invested heavily in refining and deploying LSM-backed infrastructure. Innovations such as tiered compaction, Bloom filters for efficient lookups, and write-optimized hardware integration continue to push LSM performance forward. Today, LSM trees are central to the architecture of modern data platforms, enabling scalable, write-optimized storage for everything from real-time analytics to mobile apps.
Up until this point I had simply assumed that while the whole background story of LSMs was very interesting, it was not especially relevant to XTDB. However, last week I was prompted to dig deeper after an email exchange with Rob Squire. I then stumbled on O’Neil’s 1993 paper (i.e. just one year after the 1992 LSM paper) titled "A Log-Structured History Data Access Method (LHAM)" whose introduction section neatly paints an image of the author’s wider motivations:
There are numerous applications that require on–line access to a history of business events. […] Twenty–five years ago, Schueler advocated that such a journal of events should be the future paradigm of databases [SCHUE77]. Ten years ago, Gray called the update–in–place paradigm a “poisoned apple” [GRAY81], and Copeland posed the question, “What if mass storage were free?” [COPE82], both making the case for append–only history databases. Since that time, we have observed continuing research on temporal databases, also known as multi–version databases, historical databases, or rollback databases [SNOD90, TAN93] […]
Unfortunately, one of the objections to Schueler’s 25–year–old vision has still not been overcome: How can a general–purpose database system provide efficient access to both current and historical data, especially when frequent updates of current data migrate information through the history interface at a high rate? (See [SCHUE77], p.163.) While the research on temporal data models and query languages has produced a plethora of proposals, the area of access methods for history data has been relatively neglected. This paper investigates how a recently devised access method, the Log–Structured Merge–Tree (LSM–Tree) introduced by O’Neil et al. [OCGO92], can be used for managing history data in an efficient manner.
A lot of this detail was removed from later publications on the LHAM design, which is a shame because it makes it quite clear that LSMs owe their existence (at least in part) to O’Neil’s desire to solve temporal databases. Perhaps this was already self-evident to those who carefully studied the 1996 LSM-Tree paper, which uses 'History table' examples throughout, but it was news to me!
Perhaps the most interesting thing about discovering that excerpt above is the reference to "[SCHUE77]".
Schueler’s reconsidering
In 1977, Ben-Michael Schueler (perhaps Schüler?) published a paper to "Proceedings of the IFIP Working Conference on Modelling in Data Base Management Systems" (edited by G. M. Nijssen) titled UPDATE RECONSIDERED.
This wasn’t even the first reference to Schueler’s paper that I’d encountered. Indeed it’s come up in several influential papers I’ve looked at over the years, but until this week it remained a total mystery to me. No longer!
In lieu of sharing UPDATE RECONSIDERED in its entirety (see the video at the top of the page if you want to see more), I would like to walk you through some of its contents and compare how "Schueler’s 25-year-old 47-year-old vision" stacks up today…
UPDATE == DELETE (+ optionally also an INSERT)
In the year 47 B.C., the most important Data Base of that time, the library of Alexandria was updated by a fire, leaving most of the 700,000 book scrolls as a cinder. We shall call this kind of update an Alexandria-Update (whether through fire or other causes).
Schueler begins with a witty introduction to his perspective on the folly of mutable updates across a variety of ancient and modern media, concluding that the magnetic tape was the first and only UPDATE-safe recording medium yet implemented. I’m sure he would be relieved to know that tape is still dominant in 2025.
The Information Continuum
Schueler argues that all databases are fundamentally incomplete and wrong, and then on top of that we often "invent mechanisms" which only make things worse.

Loosely paraphrasing: databases can never be perfect, because they contend with an inability to completely resolve the core problems of Entry Lag, Obsolescence, and Errors.
Minkowski Lifelines through The Information Continuum
The correct way to navigate The Information Continuum is by giving the notion of 'time' its proper treatment:
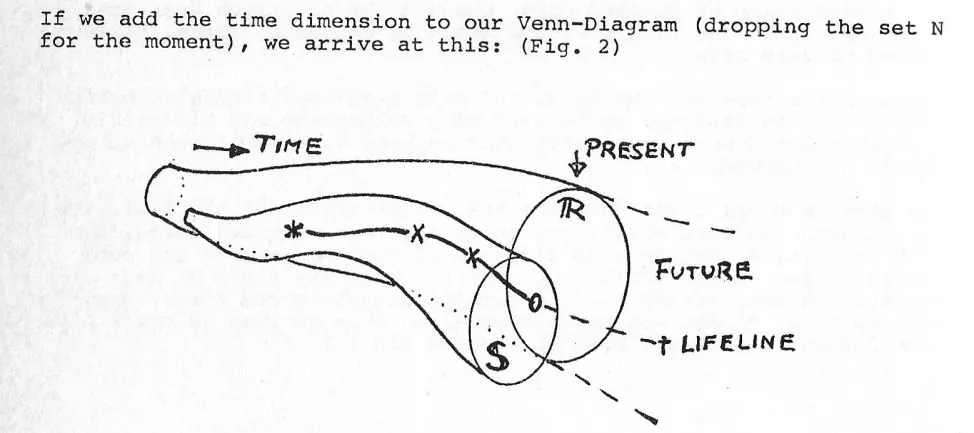
The sets will become cones and a heretofore pointlike representation of an element will become what Minkowski called a life line. As far as we are concerned, such a life line has singularities in R that effect a chance of S if S is taken to be a snapshot of the state of R. These singularities are called events. Clearly the ordered set of events contains all the information we’ll ever need.
In other words…
Events are fundamental
The crucial point here is: The set of events is stable in the sense that the only operation necessary on it is union.
Events are unchanging entities in a space-time continuum.
(Yes reader, I agree, this sounds like quite a strong argument for 'Event Sourcing'!)
The State of the Art, circa 1977
Schueler outlines the problems with databases of his era:
The hardware basis of the update is the direct access magnetic disk device. Since from the beginning the ability to change stored information has been passed on to the user (application programmer and even terminal operator) tremendous efforts have been and still are expended to counteract possible deleterious effects of this facility. [It] seems likely that an appreciable part of work on software is accountable directly or indirectly on this complex.
Sadly, I think he also just very accurately described the status quo of 2025!
For a more modern take on the widespread problems of mutability and its consequences for the software industry, I can highly recommend a look through Rich Hickey’s back catalog.
The problem of UPDATE
Every update process causes necessarily a loss of information. The responsibility for this loss is usually delegated to the user and/or is counteracted by a highly redundant backup.
It seems plausible that a very large proportion of system expenses, limitations, and insecurities is directly or indirectly attributable to the update. The problems are scattered over the whole system, including the operating system, data management system, application programs, end user behaviour, computer shop organisation, etc.
I’m not 100% sure what a "computer shop organisation" is, but I whole-heartedly believe he’s right about everything else here. In fact, rather coincidentally, I gave a talk a couple of years ago articulating many of these same points:
I don’t recall exactly how I chose the title "UPDATE Considered Harmful", but truly I had not read Schueler’s paper beforehand!
The alternative
It is clear that systems could be built at a fraction of the cost or with a multiple of the power if the update in the known traditional form could be eliminated. At the same time, reliability would increase proportionally.
A bold statement perhaps, but millions of Functional Programming advocates know there’s truth here. However, let’s be clear that Schueler is talking about data in databases here, not mere programming languages.
We have been told over and over again that we have to map a changing environment into our data systems and that quite naturally we must keep up the state description within our system with the changing world by changing our data. At the same time, we are aware of the fact that we cannot simply throw away past states because to rightly fear that circumstances will make them relevant again.
The rising importance of auditability and data compliance was clear enough to Schueler five decades ago. These are not new problems, so why are we still solving them in 2025?
But there is a set of entities that never change: Events.
If we record all events from our Universe of interest, we can arrive by inference at the complete set of state-describing cross-sections up to and including the latest surface which in most circumstances will comprise the most relevant information.
It is clear that nothing could be gained if information about events is simply compiled into a heap, leaving the user with the task of finding his needles in this growing haystack.
It would be desirable to arrange the events (we shall abbreviate "stored representation of information about an event") so, that a look into our data base will show the latest surface of the event space. At the same time it should be possible to penetrate beyond this surface along the lifelines into the past.
Again, it’s 2025, and how many databases can help us capture a Universe of interest like this? Which ones make it ergonomic and easy to use?
RECORDS over time
Schueler’s vision predated widespread acceptance of the Relational Model and the industrial success of SQL, but didn’t preclude either:

Data Manipulation
All language constituents for locating, referencing, navigating etc. of data items will work on the surface […]
It is probable that life gets easier for a lot of people if you can tell the end user he can do no harm to his own data. […]
Data validation can be deferred, allowing processing of provisional data and an assessment of dependability of results.
All of these thoughts run counter to today’s dominant SQL paradigm.
The motivation for LSMs?
Schueler makes the case for needing careful cost-performance management across storage tiers for handling large historical databases to ever be practical:
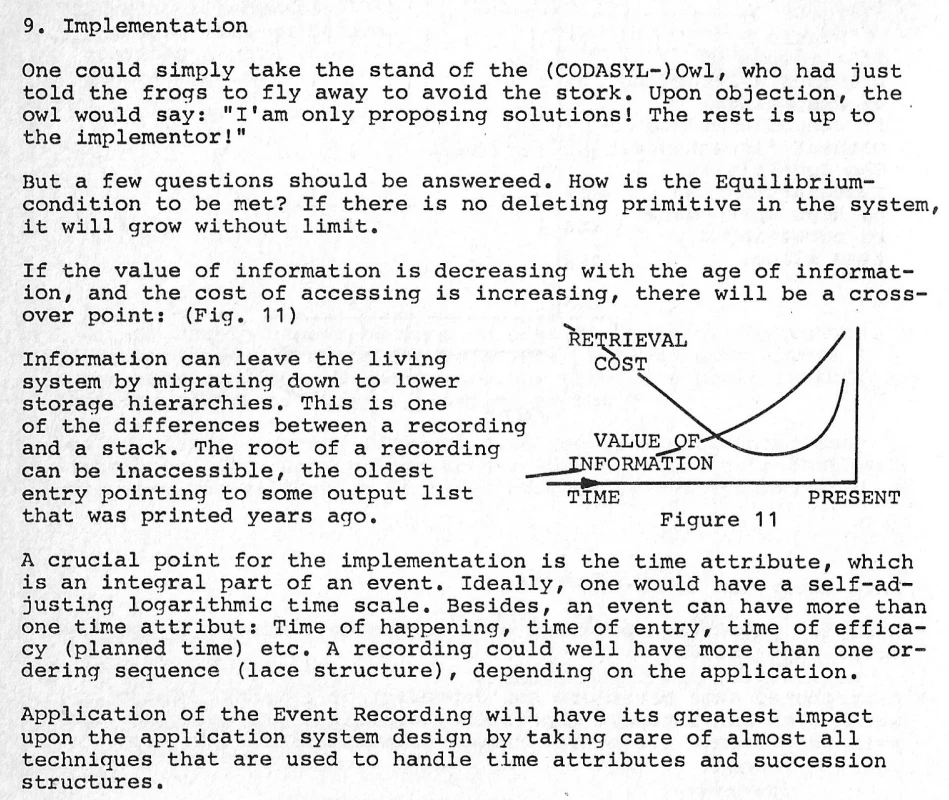
With Apache Iceberg in S3, we’re finally getting somewhere near this ideal, but without a proper handling of time surely we will still struggle to handle the initial challenges presented: Entry Lag, Obsolescence, Errors.
Distributed events and structural complications
There’s some discussion in the paper about how events can be merged from multiple sources, and how this avoids many UPDATE-related problems when building distributed database systems. Schueler points out that attempting to support merges across disparate event recordings is not necessarily easy:
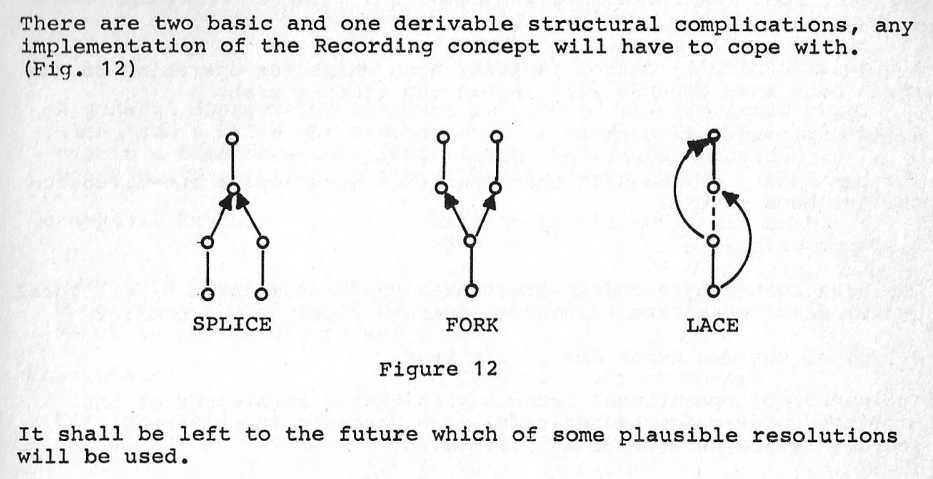
He wasn’t thinking merely about version control for source code here, his vision applies to all forms of data. But yes, he probably could have invented Git too.
Corrections
One final word about errors and correction. There seems to be no reason to erase erroneous information if it is overlaid by the correction. As long as access into a Recording is always from the surface, errors are masked effectively by correct information
This raises an important question: how should a database differentiate between 'changing' data and 'correcting' data.
Schueler’s Conclusion
No single item in this paper is original […]
The basic idea does not demand immediate action, but for one plea: Any model of a conceptual schema for DBMS’s should be kept open along the time dimension.
Can XTDB deliver?
Through a remarkable twist of fate, without us being directly aware of it before now, it seems UPDATE RECONSIDERED has essentially summarised and justified why we’re working on XTDB in the first place.
Schueler’s vision is still a distant dream for most developers and businesses. Hardware has evolved dramatically, Mass Storage Is Now Free (relative to 1977 at least), yet our databases still don’t give time and the problem of UPDATE the proper treatment, and so we all pay the price every day. Trillions of tiny paper cuts and untold human-centuries of potential wasted on modeling mistakes, integration failures and data loss.
We can do better. We must!
Schueler didn’t totally describe the 'bitemporal model' in this paper, but it was clearly an inspiration to Richard Snodgrass and the many others who have pushed the vision of a temporal database forward over the years.
As Kent Beck puts it:
You may have heard the word “bi-temporal”. What’s that about?
In a nutshell, we want what’s recorded in the system to match the real world. We know this is impossible (delays, mistakes, changes) but are getting as close as we can. The promise is that if what’s in the system matches the real world as closely as possible, costs go down, customer satisfaction goes up, & we are able to scale further faster.
XTDB is a bitemporal database that aims to 'get time right' without sacrificing the declarative power of SQL. Our implementation already deeply aligns with many of Schueler’s considerations, and we hope he might approve of what we’ve built: a database system capable of tackling the hard problems of Entry Lag, Obsolescence, and Errors.
Afterword: Schueler’s mystery
I would love to learn more about Schueler - where he worked, his interests, and what else he published (etc.) - but it seems very little is available on the web. In fact the only other promising thread found relating to his name was this very brief reference in a book about German computer history:
Schüler, Ben-Michael: Beitrag zur Geschichte des Magnetons von den ersten Schallaufzeichnungen zum Tonband. Techn. Rdsch. Bern 53
Which roughly translates to "Schüler, Ben-Michael: Contribution to the History of the Magneton from the First Sound Recordings to Tape. Techn. Rdsch. Bern 53" - I can’t confirm it’s the same person, but I’d say it certainly matches the profile!
Discuss!
What do you think? Was Schueler a prophetic genius? Join us in the comments!
